I’ve hooked up jstut’s (formerly narscribblus‘) narcissus-based parser and jsctags-based abstract interpreter up to the ajax.org code editor (ace, to be the basis for skywriter, the renamed and somewhat rewritten bespin). Ace’s built-in syntax highlighters are based on the somewhat traditional regex-based state machine pattern and have no deep understanding of JS. The tokenizers have a very limited stateful-ness; they are line-centric and the only state is the state of the parser at the conclusion of tokenizing the previous line. The advantage is that they will tend to be somewhat resilient in the face of syntax errors.
In contrast, narcissus is a recursive descent parser that explodes when it encounters a parse error (and takes all the state on the stack at the point of failure with it). Accordingly, my jstut/narscribblus parser is exposed to ace through a hybrid tokenizer that uses the proper narcissus parser as its primary source of tokens and falls back to the regex state machine tokenizer for lines that the parser cannot provide tokens for. I have thus far made some attempt at handling invalidation regions in a respectable fashion but it appears ace is pretty cavalier in terms of invalidating from the edit point to infinity, so it doesn’t really help all that much.
Whenever a successful parse occurs, the abstract interpreter is kicked off which goes and attempts to evaluate the document. This includes special support for CommonJS require() and CommonJS AMD define() operations. The require(“wmsy/wmsy”) in the screenshot above actually retrieves the wmsy/wmsy module (using the RequireJS configuration), parses it using narcissus, parses the documentation blocks using jstut, performs abstract interpretation and follow-on munging, and then returns the contents of that namespace (asynchronously using promises) to the abstract interpreter for the body of the text editor. The hybrid tokenizer does keep around a copy of the last good parse to deal with code completion in the very likely case where the intermediate stages of writing new code result in parse failures. Analysis of the delta from the last good parse is used in conjunction with the last good parse to (attempt to) provide useful code completion
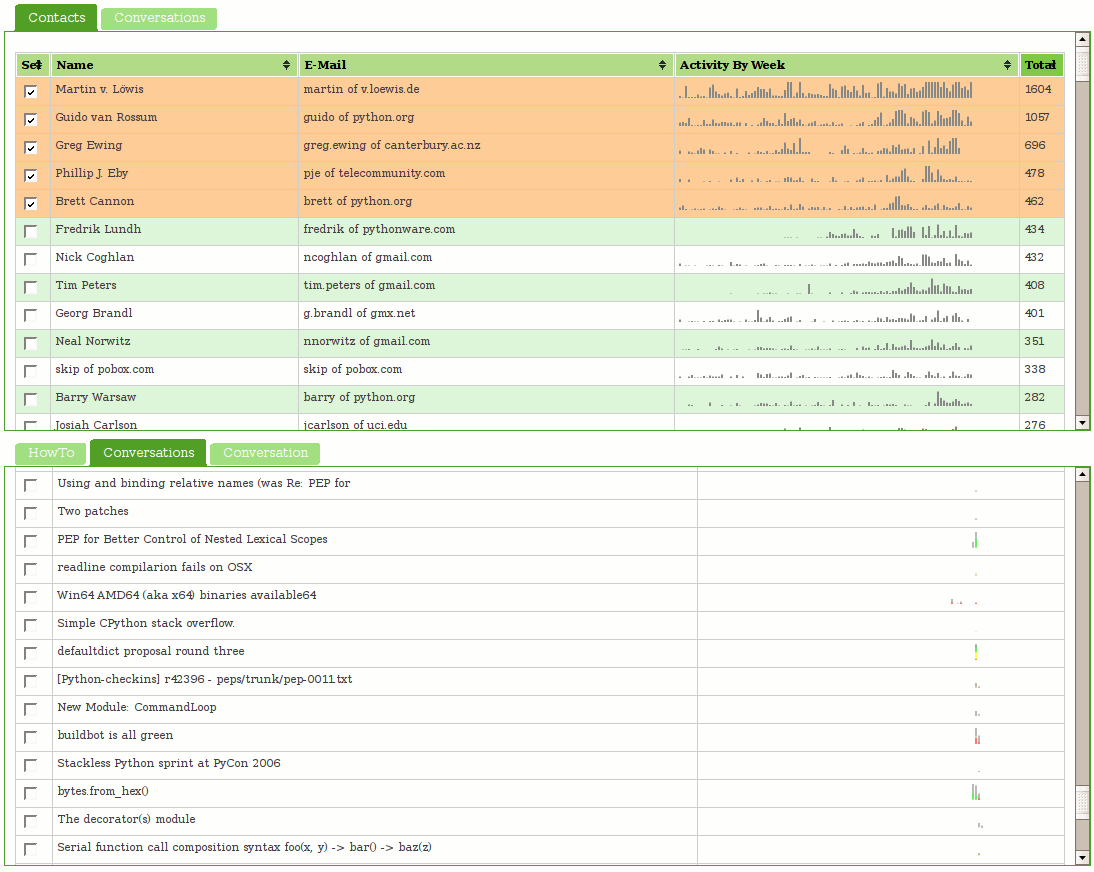
The net result is that we have semantic information about many of the tokens on the screen and could do fancy syntax highlighting like Eclipse can do. For example, global variables could be highlighted specially, types defines from third party libraries could get their own color, etc. For the purposes of code completion, we are able to determine the context surrounding the cursor and the appropriate data types to use as the basis for completion. For example, in the first screenshot, we are able to determine that we are completing a child of “wy” which we know to be an instance of type WmsyDomain from the wmsy namespace. We know the children of the prototype of WmsyDomain and are able to subsequently filter on the letter “d” which we know has been (effectively) typed based on the position of the cursor. (Note: completion items are currently not sorted bur rather shown in definition order.)

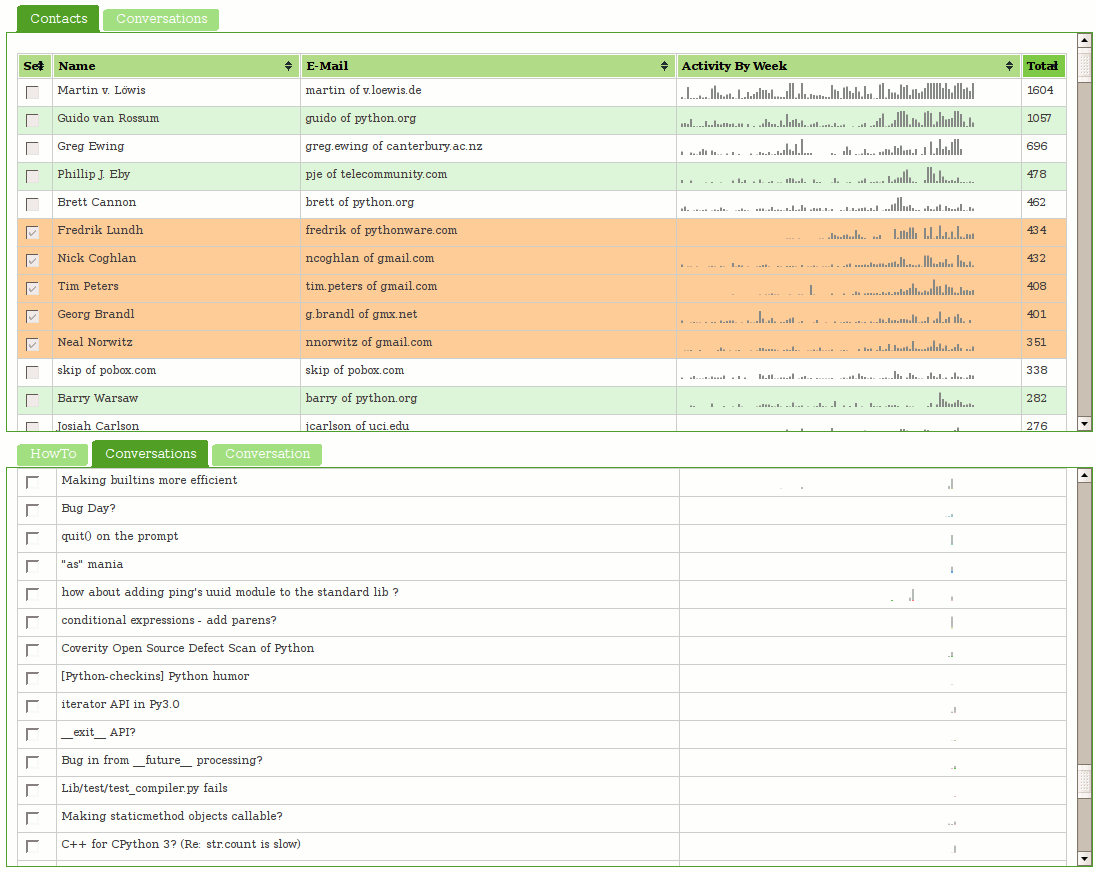
In the second example, we are able to determine that the cursor is in an object initializer, that the object initializer is the first argument of a call to defineWidget on “wy” (which we know about as previously described). We accordingly know the type constraint on the object initializer and thus know the legal/documented key names that can be used.
This is not working enough to point people at a live demo, but it is exciting enough to post teaser screenshots. Of course, the code is always available for the intrepid: jstut/narscribblus, wmsy. In a nutshell, you can hit “Alt-/” and the auto-completion code will try and do its thing. It will display its results in a wmsy popup that is not unified with ace in terms of how focus is handled (wmsy’s bad). Nothing you do will actually insert text, but if you click outside of the popup or hit escape it will at least go away. The egregious deficiencies are likely to go away soon, but I am very aware and everyone else should be aware that getting this to a production-quality state you can use on multi-thousand line files with complex control flow would likely be quite difficult (although if people document their types/signatures, maybe not so bad). And I’m not planning to pursue that (for the time being); the goal is still interactive, editable, tutorial-style examples. And for these, the complexity is way down low.
My thanks to the ajax.org and skywriter teams; even at this early state of external and source documentation it was pretty easy to figure out how various parts worked so as to integrate my hybrid tokenizer and hook keyboard commands up. (Caveat: I am doing some hacky things… :)) I am looking forward to the continued evolution and improvement of an already great text editor component!