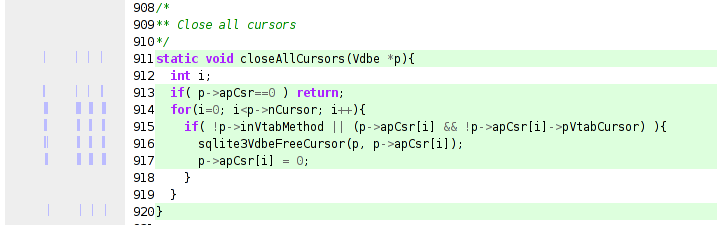
type "mbt", see this.
gdb has had integrated python support for some time and it is truly awesome. The innards have changed here and there, so my previous efforts to show colorized/fancy backtraces, show colorized source listings, and provide unified JS/C++ mozilla backtraces (with colors still) have experienced some bit-rot over time.

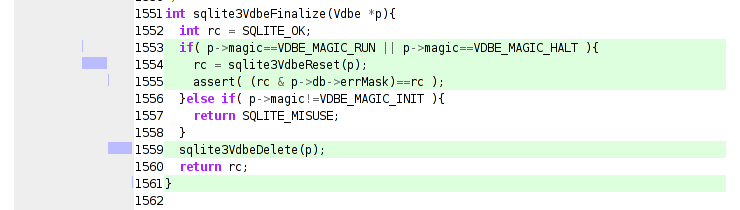
type "cbt", see this
I have de-bitrotted the changes, hard. Hard in this case means that the changes depend on gdb 7.3 which only exists in the future or in the archer repo you can find on this wiki page, or maybe in gdb upstream but I already had the archer repo checked out…

type "sl", see this.
In any event, if you like gdb and work with mozilla, you will not only want these things, but also Jim Blandy’s mozilla-archer repo which has magic SpiderMonkey JS helpers (one of which mozbt depends on; those JSStrings are crazy, yo!). Coincidentally, he also depends on the future, and his README tells you how to check out the archer branch in greater detail.
You can get your own copy of these very exciting gdb python things from my github pythongdb-gaudy repo.
The important notes for the unified backtrace are:
- It does’t work with the tracing JIT; the trace JIT doesn’t produce the required frames during its normal operation.
- It might work with the method JIT if gdb could unwind method JIT frames, but it doesn’t seem to do that yet. (Or I didn’t build with the right flag to tell it to use a frame pointer/etc., or I am using the wrong gdb branch/etc.) Once the Method JIT starts telling gdb about its generated code with debug symbols and the performance issues in gdb’s JIT interface are dealt with, you can just use the colorizing backtrace because no special logic is required to interleave frames at that point and Jim Blandy’s magic JS pretty printers should ‘just work’.
- Don’t forget that if you just want a pure JS backtrace (and with all kinds of fanciness) and have a debug build, you can just do “call DumpJSStack()” in gdb and it will call back into XPConnect and invoke the C++ code that authoritatively knows how to walk this stuff.
- If you’re cool and using generators, then you’re stuck with the interpreter, so it will totally work.