
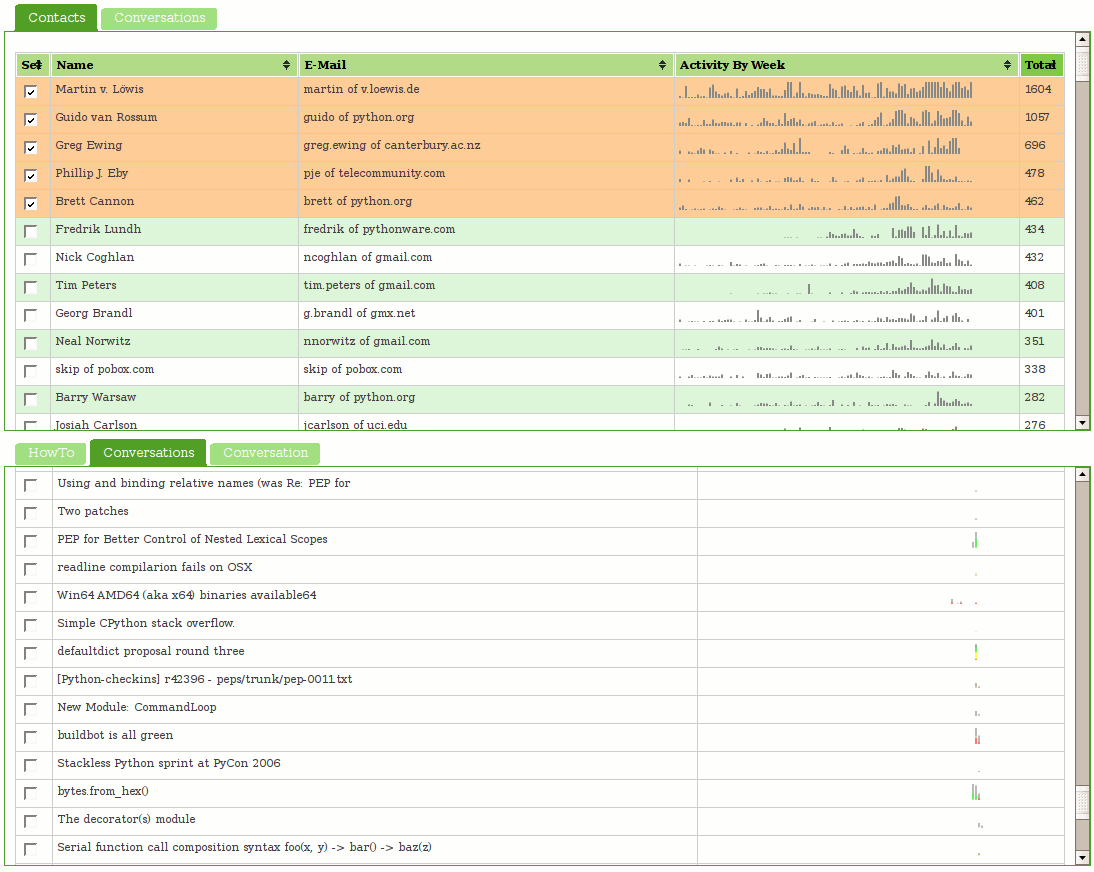
Visotank now allows you to select some authors of interest from a sortable list of contacts, and then show the conversations they were involved in. You get the previously shown sparkbars for the author’s activity. You also get sparkbars showing the conversation activity, with each author assigned a color and consistent stacking position in that sparkbar. Click on the screenshots for zoomed versions of the screenshots to see what I mean.
You can click on things yourself at http://clicky.visophyte.org:8080/. Please only go there if you’re okay with restarting your Firefox session (especially true if Firebug is on.) All tables/images are the real thing and not fetched on demand… which results in Firefox having to pull down a lot of images. Click on some rows in the contacts table to select them. Then, in the lower tab group, click on the “conversations” tab. This will then fetch all the conversations those selected users were involved in. The system will truncate more than 10 users, so don’t go crazy. The tabs are re-fetched on switch, so if you change your contact selections, in the lower tab group, click away to “HowTo”, then back to “Conversations”. The “Conversation” tab does nothing and is a big lie. Great UI, I know.
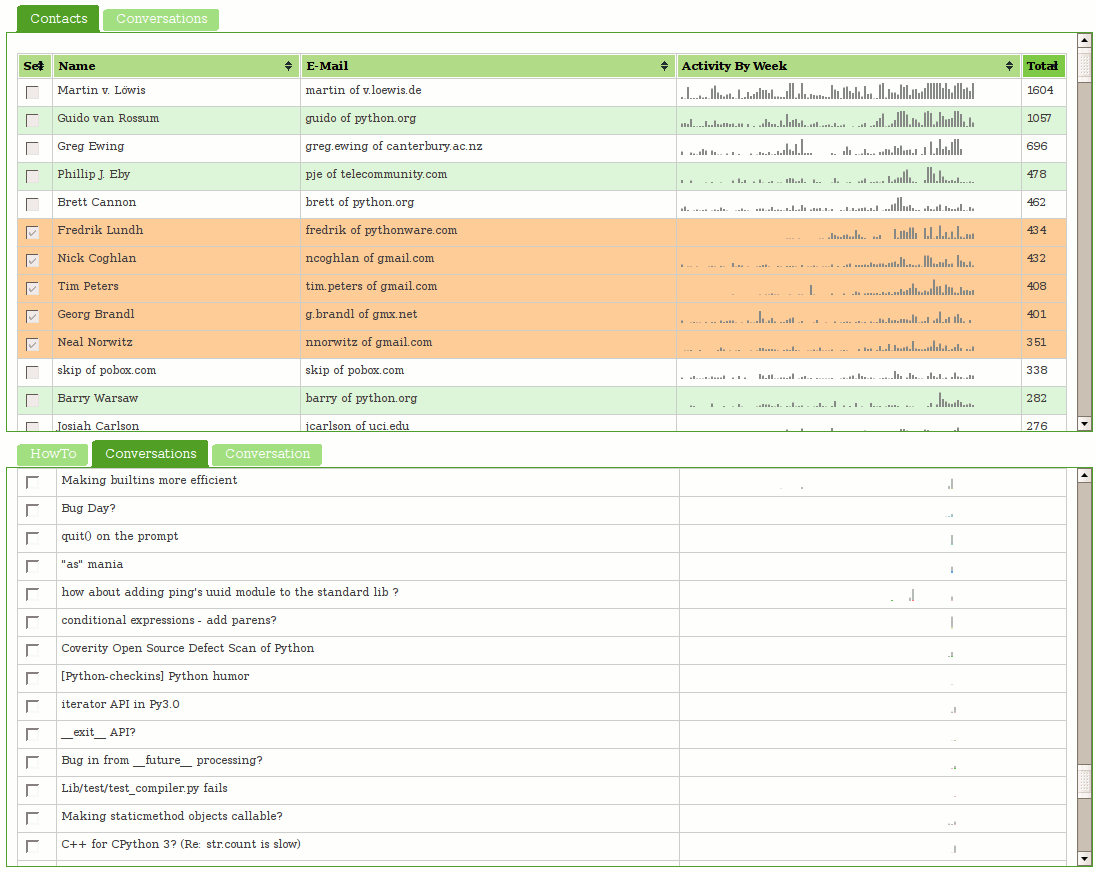
I think you will find that sparkbar visualizations of the conversation traffic with a weekly granularity are rather useless. I think a reasonable solution would be a ‘zoomed’ sparkbar with an indication of the actual uniform timeline scale included. Since the images currently show about 2 years of data, a thread that happened 1 year ago would be centered in the middle of the image, but with its actual horizontal scale being inconsistent with that position. Future work, as always.
I have used Pylon’s Beaker caching layer to attempt to make things reasonably responsive. While CouchDB view updates are sadly quite lengthy (many many minutes when dealing with 16k messages; python-dev from Jan 2006 through Nov 2007), that is thankfully a one-off sort of thing. (The data-set is immutable once imported and I don’t change schemas that often.) The main performance hit is that I can only issue one range of keys to query in a request, so if I am trying to snipe a subset of non-consecutive information, I have to issue multiple requests. (I don’t believe POSTed views can operate against views in the database…)
Regrettably, I think my conclusion about CouchDB is that it (or something like it) will be truly fantastic in the future, but it is not going to get there soon enough for anything that hopes to be ‘productized’ anytime soon. The next thing I want to look at is using a triple-store to model some of the email data schema; my efforts from the visterity hacking suggest it could be quite useful. Of course, even if triple stores work out, I suspect a more traditional SQL database will still be required for some things. Combined with a thin custom aggregation and caching layer, that could work out well.
Note: I should emphasize that my CouchDB schema could be more optimized, but part of the experiment is/was to see if the views saved me from having to jump through clever hoops.