
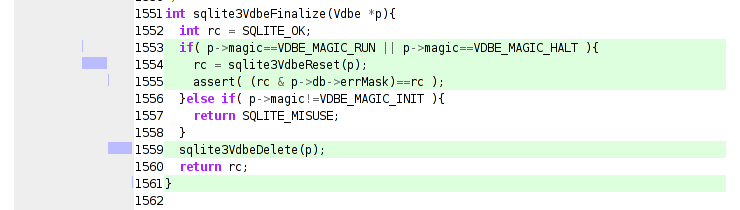
Python code driving gdb via the mi2 interface (using pexpect and pyparsing) begets a trace file. Python code processing the trace file begets an html document (with syntax highlighting thanks to pygments.) The above is just a screenshot of the output, which you can actually browse here.
The “visualization” is pretty simple. Lines of code with a light green background were executed in the trace. 15 lines of context are shown around executed lines of code. The bars to the left show when the line of code was executed during the trace. If the code was a function call, its bar is extended until the function call completed based on conclusions drawn from knowing the stack depth at each step. There is currently no way to visually distinguish from the graphic between a line executed many times in rapid succession and a call that lasted a long time. You would need to either look at the code or cheat and use firebug.
The visualization is of a call to commit() using pysqlite2 on sqlite3 which fails because of an outstanding select that has not yet had all its rows retrieved. My conclusion is that clever generator tricks (not mine!) can bite you when any piece of your stack has concurrency issues… and pysqlite2 should report the most specific error string possible. (Going to provide a patch; still think the trunk would provide the rather generic error that bit me.) For those using trac’s version control abstraction, be warned that changeset traversal is most definitely a (logic) generator wrapping a row-results-fetching generator.
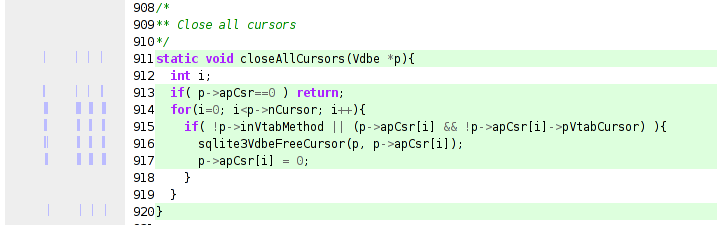
The tracing mechanism is pretty straight-forward. The tracing class is told an interesting breakpoint and an ignore count. Once the count has been reached, “step” tracing begins. The idea was to do a first pass that just counts how many times the interesting breakpoint occurs before the program tanks, then we can skip to the last few before doing the (slow) step-wise tracing in the second pass. The goal would be to approximate a light-weight tracing mechanism where we can see what the program did before whatever bad state occurred. Gah! I was just going to say that there aren’t any open source tools readily available to accomplish that goal (dyninst/dpcl still require a bit of legwork), but it turns out that Chronicle (formerly Amber) has recently been released. (For whatever reason, Robert O’Callahan’s post didn’t show up in his feed via planet mozilla for me.) OTOH, this method is still potentially useful for remote gdb target debugging on actual hardware (albeit extremely slowly), or perhaps for a case where the program must do a lot of execution before the interesting part of the trace happens, lending itself to a non-valgrind solution. I presume you would pay the simulation price for valgrind the whole way through, unless valgrind can ‘absorb’ a running process into its simulation.
I also have a visualization done using visophyte’s model abstraction (if you are going to go and invent yet another multi-backend canvas abstraction layer, you might as well use it), but without some way to view the corresponding code and explore, it is useless. The generated HTML here is more useful, but still lacking in interactivity or true context. That would be the next step. The step after that would be throwing back in a concise and interactive visualization. The same effort required for that should allow me to produce interactive visualizations from thunderbird.