I am doing something where I need to talk to the Mozilla hg pushlog. I noticed things were running disturbingly slow, so I figured I’d look into it. I’m using node.js so htracr (a node.js, libpcap-based via node_pcap http transaction visualizer) seemed like the easiest and most fun way to figure out what is going on. (In a web browser I would just use the built-in timeline.)


slooooooooooow...
The short request is a comm-central pushlog request by date. The long request is a mozilla-central pushlog request by date. mozilla-central has more pushes, suggesting that the query is either doing something sketchy like a table scan or there is lock contention. Quick investigation showed no successful pushes in the given timeframe, eliminating lock contention from the likely list of causes. (The implementation uses SQLite, which, when not running with the Write-Ahead-Log enabled, will only experience contention when the reads are occurring from separate connections.)
This suggests the query is doing a table scan. This tends to be a reasonably straightforward problem. But since I have a SQLite opcode visualizer in my toolkit (now on github!) that needs plugs periodically to keep it on the tip of everyone’s tongue, I used that. Plug! Plug! Plug!
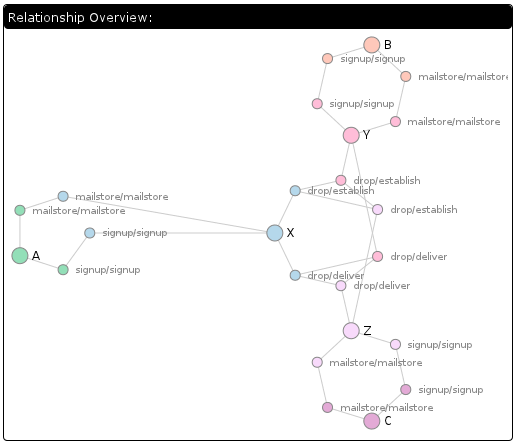
If you care about these kind of things, click on the small image on the left and look for the red text. The giant warning flag is the “Rewind” on the changesets table and the control flow that performs a “Next” that appears to be part of a loop case right off the bat. (Note that this is using SQLite 3.6.23.1 since I assume that’s what hg.mozilla.org is using.) Summary: we perform one table scan of the changesets table for every push in the date range.
The “bad” schema is:
CREATE TABLE changesets (pushid INTEGER, rev INTEGER, node text);
CREATE TABLE pushlog (id INTEGER PRIMARY KEY AUTOINCREMENT, user TEXT, date INTEGER);
CREATE UNIQUE INDEX changeset_node ON changesets (node);
CREATE UNIQUE INDEX changeset_rev ON changesets (rev);
CREATE INDEX pushlog_date ON pushlog (date);
CREATE INDEX pushlog_user ON pushlog (user)
The query is: SELECT id, user, date, node from pushlog LEFT JOIN changesets ON id = pushid WHERE date > 1298306930 AND date < 1298306955 ORDER BY id DESC, rev DESC;
The query plan via EXPLAIN QUERY PLAN from SQLite 3.6.23.1 on the “bad” schema is:
0|0|TABLE pushlog WITH INDEX pushlog_date
1|1|TABLE changesets
This is obvious if you know what you’re looking for; unfortunately the indication of the problem is the lack of “WITH INDEX” or the like rather than text that calls out the problem. The much nicer SQLite 3.7.4 EXPLAIN QUERY PLAN (which has great documentation!) would make the problem much more obvious by saying “SCAN TABLE” if not for the fact that it ends up creating an automatic index:
0|0|0|SEARCH TABLE pushlog USING INDEX pushlog_date (date>? AND date<?) (~110000 rows)
0|1|1|SEARCH TABLE changesets USING AUTOMATIC COVERING INDEX (pushid=?) (~7 rows)
0|0|0|USE TEMP B-TREE FOR ORDER BY
Although one table scan accompanied by a b-tree building is probably a better idea than N table scans, if you read this and think “SQLite 3.7.x just saved someone’s bacon”, you would be wrong because it still throws away the index at the end. The server is still experiencing an initial vicious kick in the pants every time the statement is run; there are just no lighter follow-up kicks (lighter because of the OS disk cache, you see…).
 In any event, the problem is that there is no index on the pushid column in the changesets table. (And pushid can’t be the primary key because it is not unique. There’s no benefit to using a composite key since SQLite will still create a simple rowid key once we use a composite, so an index is the way to go.)
In any event, the problem is that there is no index on the pushid column in the changesets table. (And pushid can’t be the primary key because it is not unique. There’s no benefit to using a composite key since SQLite will still create a simple rowid key once we use a composite, so an index is the way to go.)
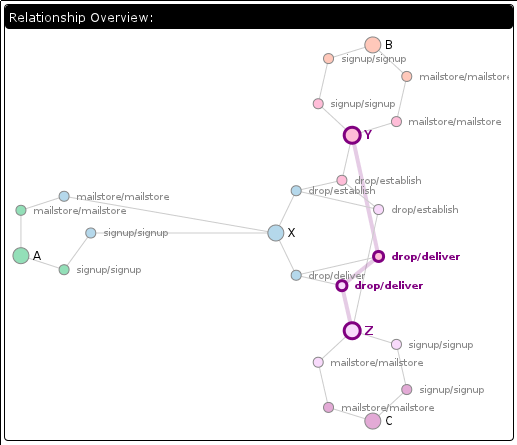
Once we fix this, our graph looks like the second one at left (in SQLite 3.6.23.1). Again, looking for red text and now also orange text, the key things are that we no longer have a “Rewind” or “Next”, and instead have a SeekGe on the index and a Seek on the table using the row id the index told us about. (We are not using a covering index because we expect extremely high locality in the table based on rowid because the insertions happen consecutively in a single transaction.)
The 3.6.23.1 query plan now looks like:
0|0|TABLE pushlog WITH INDEX pushlog_date
1|1|TABLE changesets WITH INDEX changeset_pushid
Much nicer! What does the lovely 3.7.4 say?:
0|0|0|SEARCH TABLE pushlog USING INDEX pushlog_date (date>? AND date<?) (~110000 rows)
0|1|1|SEARCH TABLE changesets USING INDEX changeset_pushid (pushid=?) (~10 rows)
0|0|0|USE TEMP B-TREE FOR ORDER BY
Awww yeah. Anywho, here’s the schema one wants to use:
CREATE TABLE changesets (pushid INTEGER, rev INTEGER, node text);
CREATE TABLE pushlog (id INTEGER PRIMARY KEY AUTOINCREMENT, user TEXT, date INTEGER);
CREATE INDEX changeset_pushid ON changesets (pushid);
CREATE UNIQUE INDEX changeset_node ON changesets (node);
CREATE UNIQUE INDEX changeset_rev ON changesets (rev);
CREATE INDEX pushlog_date ON pushlog (date);
CREATE INDEX pushlog_user ON pushlog (user);
I am off to file this as a bug… filed as bug 635765.
UPDATE: I initially had a brain glitch where I proposed using a primary key rather than an additional index. Unfortunately, this is what got pushed out to feed readers during the 30 seconds before I realized my massive mistake. If you have come to this page to note the bad-idea-ness of that, please enjoy the corrected blog-post which explains why the primary key is not the best idea before going on to point out any other serious brain glitches 🙂
UPDATE 2 (Feb 22, 2011): Good news: the change has landed and all the existing databases have been updated. Woo! Bad news: although things are probably faster now, things are still way too slow. (Given that this specific deficiency was determined by inspection and not actual profiling, this is not so surprising.) It would appear that the retrieval of the information about the changesets is the cause of the slowdown. More inspection on my part suggests that populating the list of tags may be involved, but that’s just a quick guess. Please follow the bug or follow-on bugs if you want to witness the entire exciting saga.