
beets is the extensible music database tool every programmer with a music collection has dreamed of writing. At its simplest it’s a clever tagger that can normalize your music against the MusicBrainz database and then store the results in a searchable SQLite database. But with plugins it can fetch album art, use the Discogs music database for tagging too, calculate ReplayGain values for all your music, integrate meta-data from The Echo Nest, etc. It even has a Music Player Daemon server-mode (bpd) and a simple HTML interface (web) that lets you search for tracks and play them in your browse using the HTML5 audio tag.
I’ve tried a lot of music players through the years (alphabetically: amarok, banshee, exaile, quodlibet, rhythmbox). They all are great music players and (at least!) satisfy the traditional Artist/Album/Track hierarchy use-case, but when you exceed 20,000 tracks and you have a lot of compilation cd’s, that frequently ends up not being enough. Extending them usually turned out to be too hard / not fun enough, although sometimes it was just a question of time and seeking greener pastures.
But enough context; if you’re reading my blog you probably are on board with the web platform being the greatest platform ever. The notable bits of the implementation are:
- Server-wise, it’s a mash-up of beets’ MPD-alike plugin bpd and its web plugin. Rather than needing to speak the MPD protocol over TCP to get your server to play music, you can just hit it with an HTTP POST and it will enqueue and play the song. Server-sent events/EventSource are used to let the web UI hypothetically update as things happen on the server. Right now the client can indeed tell the server to play a song and hear an update via the EventSource channel, but there’s almost certainly a resource leak on the server-side and there’s a lot more web/bpd interlinking required to get it reliable. (Python’s Flask is neat, but I’m not yet clear on how to properly manage the life-cycle of a long-lived request that only dies when the connection dies since I’m seeing the appcontext get torn down even before the generator starts running.)
- The client is implemented in Polymer on top of some simple backbone.js collections that build on the existing logic from the beets web plugin.
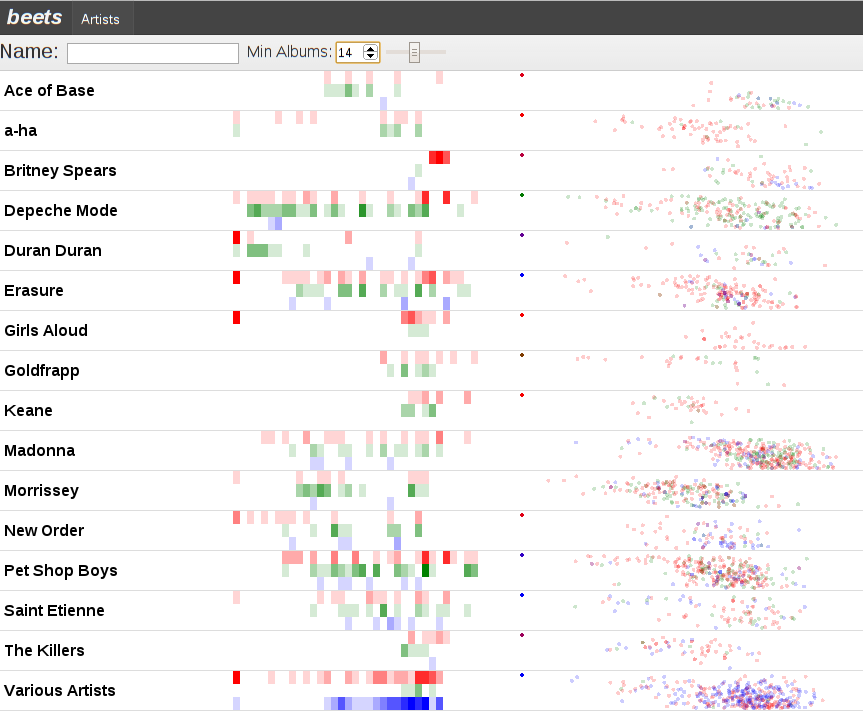
- The artist list uses the polymer-virtual-list element which is important if you’re going to be scrolling through a ton of artists. The implementation is page-based; you tell it how many pages you want and how many items are on each page. As you scroll it fires events that compel you to generate the appropriate page. It’s an interesting implementation:
- Pages are allowed to be variable height and therefore their contents are too, although a fixedHeight mode is also supported.
- In variable-height mode, scroll offsets are translated to page positions by guessing the page based on the height of the first page and then walking up/down from there based on cached page-sizes until the right page size is found. If there is missing information because the user managed to trigger a huge jump, extrapolation is performed based on the average item size from the first page.
- Any changes to the contents of the list regrettably require discarding all existing pages/bindings. At this time there is no way to indicate a splice at a certain point that should simply result in a displacement of the existing items.
- Albums are loaded in batches from the server and artists dynamically derived from them. Although this would allow for the UI to update as things are retrieved, the virtual-list invalidation issue concerned me enough to have the artist-list defer initialization until all albums are loaded. On my machine a couple thousand albums load pretty quickly, so this isn’t a huge deal.
- There’s filtering by artist name and number of albums in the database by that artist built on backbone-filtered-collection. The latter one is important to me because scrolling through hundreds of artists where I might only own one cd or not even one whole cd is annoying. (Although the latter is somewhat addressed currently by only using the albumartist for the artist generation so various artists compilations don’t clutter things up.)
- If you click on an artist it plays the first track (numerically) from the first album (alphabetically) associated with the artist. This does limit the songs you can listen to somewhat…
- visualizations are done using d3.js; one svg per visualization
- The artist list uses the polymer-virtual-list element which is important if you’re going to be scrolling through a ton of artists. The implementation is page-based; you tell it how many pages you want and how many items are on each page. As you scroll it fires events that compel you to generate the appropriate page. It’s an interesting implementation:

“What’s with all those tastefully chosen colors?” is what you are probably asking yourself. The answer? Two things!
- A visualization of albums/releases in the database by time, heat-map style.
- We bin all of the albums that beets knows about by year. In this case we assume that 1980 is the first interesting year and so put 1979 and everything before it (including albums without a year) in the very first bin on the left. The current year is the rightmost bucket.
- We vertically divide the albums into “albums” (red), “singles” (green), and “compilations” (blue). This is accomplished by taking the MusicBrainz Release Group / Types and mapping them down to our smaller space.
- The more albums in a bin, the stronger the color.
- A scatter-plot using the echo nest‘s acoustic attributes for the tracks where:
- the x-axis is “danceability”. Things to the left are less danceable. Things to the right are more danceable.
- the y-axis is “valence” which they define as “the musical positiveness conveyed by a track”. Things near the top are sadder, things near the bottom are happier.
- the colors are based on the type of album the track is from. The idea was that singles tend to have remixes on them, so it’s interesting if we always see a big cluster of green remixes to the right.
- tracks without the relevant data all end up in the upper-left corner. There are a lot of these. The echo nest is extremely generous in allowing non-commercial use of their API, but they limit you to 20 requests per minute and at this point the beets echonest plugin needs to upload (transcoded) versions of all my tracks since my music collection is apparently more esoteric than what the servers already have fingerprints for.
Together these visualizations let us infer:
- Madonna is more dancey than Morrissey! Shocking, right?
- I bought the Morrissey singles box sets. And I got ripped off because there’s a distinct lack of green dots over on the right side.
Code is currently in the webpd branch of my beets fork although I should probably try and split it out into a separate repo. You need to enable the webpd plugin like you would any other plugin for it to work. There’s still a lot lot lot more work to be done for it to be usable, but I think it’s neat already. It definitely works in Firefox and Chrome.